
Kuma's Curious Paradise
성능 개선기 : fetch join과 pagination 을 함께 사용할 때의 문제 해결 + 캐시로 인한 성능 개선 본문
유레카 미니 프로젝트2 발표 도중 캐시로 성능이 얼마나 향상되었냐는 질문을 받았다. 그럼 jmeter로 확인해보면 되지! 일단 캐시가 적용된 상태를 체크해보자! 하던 도중… 예상치 못한 상황을 만났다.
문제1 : 캐시가 제대로 적용되지 않았다
아래는 테스트 설정이다. 500개의 스레드가 60초 동안 차례로 들어온다. 각 스레드들은 200초까지 유지된다.

캐시를 적용한 채 getRanking을 테스트해 보았다. 시간이 좀 지나자 에러가 터지고… 서버가 마비되기 시작했다.
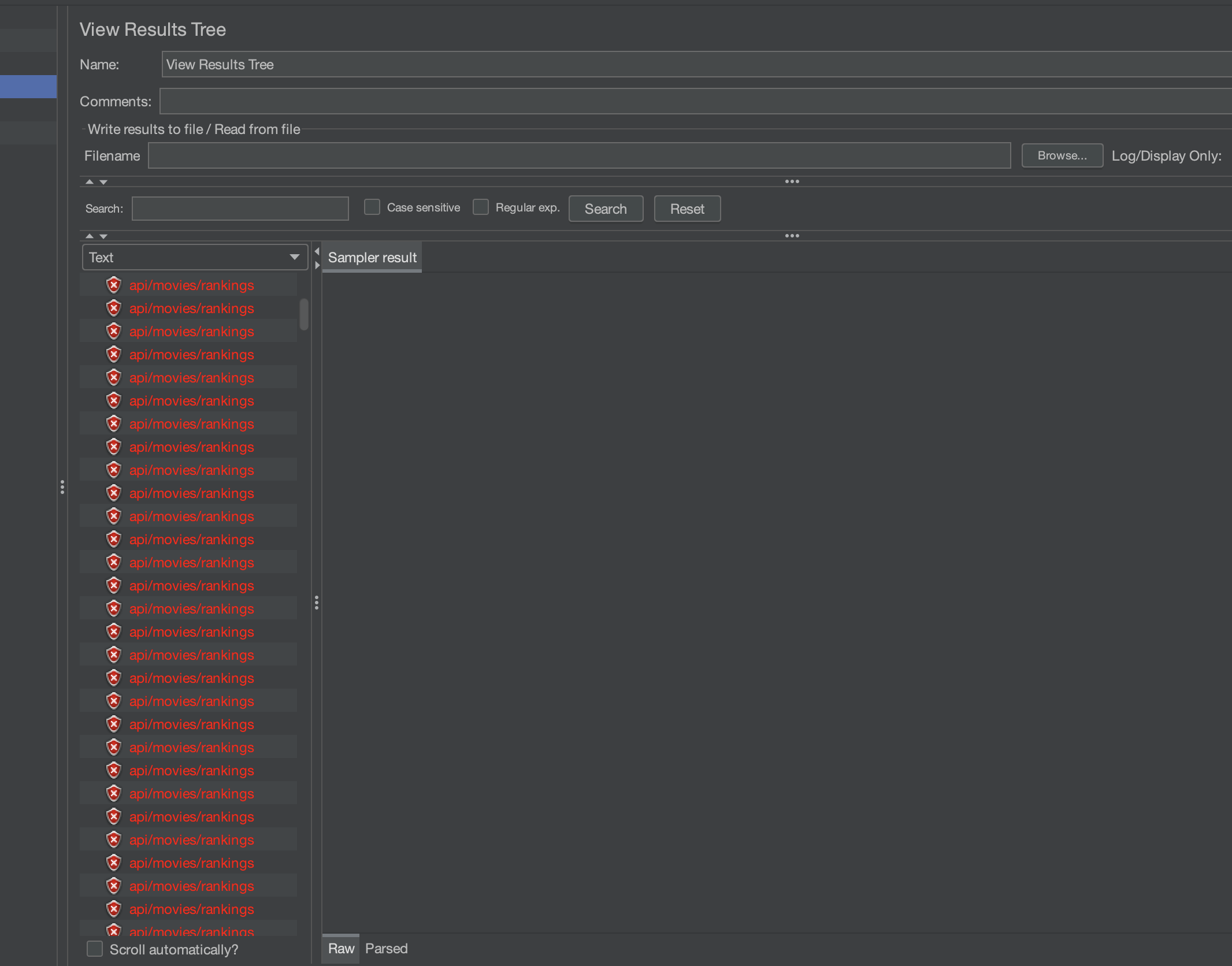
- 117,078: 117,078개의 요청이 처리되었다. 이는 캐시 적용 시 서버가 처리한 전체 요청 수를 의미한다.
- 676 ms: 평균 응답 시간. 이는 각 요청에 대해 서버가 응답하는 데 걸린 평균 시간을 나타낸다. 캐시 적용 시 응답 시간이 얼마나 줄어들었는지 비교하는 것이 중요하다.
- Min: 2 ms, Max: 4580 ms: 가장 짧은 응답 시간은 2밀리초, 가장 긴 응답 시간은 4580밀리초이다. 캐시 미스가 발생하거나 부하가 높은 상황에서 최대 4.5초의 응답 시간을 기록하였다.
- 312.61 ms: 응답 시간의 표준 편차는 312.61밀리초로, 이는 응답 시간이 평균에서 얼마나 벗어나는지를 나타낸다. 표준 편차가 크다면 일부 요청이 매우 오래 걸렸다는 것을 의미한다. 아직 비교균이 없으므로 이후에 판단내리기로 한다.
- 620.7 requests/sec: 초당 620.7개의 요청을 처리할 수 있음을 나타낸다. 이 값은 캐시를 사용했을 때 서버의 처리량을 보여준다. 캐시 미적용 시 처리량과 비교해 얼마나 개선되었는지 확인하는 것이 중요하다.
- Received: 3464.17 KB/sec, Sent: 81.48 KB/sec: 서버가 초당 수신한 데이터는 3464.17KB, 송신한 데이터는 81.48KB이다. 이는 서버의 네트워크 입출력 성능을 의미한다.
- 5715.2: 요청당 평균 5715.2바이트의 데이터가 처리되었다.
아래는 서버의 로그다.
2024-09-25T16:35:49.818+09:00 INFO 34379 --- [MoviePedia] [e [_default_]-0] c.s.m.common.cache.CacheEventLogger : Cache event occurred - Key: 2024-09-25T16:35:49.467252, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@73f07734
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
2024-09-25T16:35:49.819+09:00 WARN 34379 --- [MoviePedia] [io-8080-exec-93] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
Hibernate: select count(m1_0.movie_id) from movie m1_0
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
Hibernate: select distinct m1_0.movie_id,m1_0.description,m1_0.director,g1_0.genre_id,g1_0.genre_name,m1_0.image_url,m1_0.release_date,m1_0.release_state,m1_0.reservation_rate,r1_0.movie_id,r1_0.review_id,r1_0.content,r1_0.member_id,m1_0.title from movie m1_0 left join genre g1_0 on g1_0.genre_id=m1_0.genre_id left join review r1_0 on m1_0.movie_id=r1_0.movie_id
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
2024-09-25T16:35:49.820+09:00 WARN 34379 --- [MoviePedia] [o-8080-exec-109] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
Hibernate: select distinct m1_0.movie_id,m1_0.description,m1_0.director,g1_0.genre_id,g1_0.genre_name,m1_0.image_url,m1_0.release_date,m1_0.release_state,m1_0.reservation_rate,r1_0.movie_id,r1_0.review_id,r1_0.content,r1_0.member_id,m1_0.title from movie m1_0 left join genre g1_0 on g1_0.genre_id=m1_0.genre_id left join review r1_0 on m1_0.movie_id=r1_0.movie_id
Hibernate: select count(m1_0.movie_id) from movie m1_0
.
.
.
2024-09-25T16:35:51.637+09:00 INFO 34379 --- [MoviePedia] [e [_default_]-0] c.s.m.common.cache.CacheEventLogger : Cache event occurred - Key: 2024-09-25T16:35:51.267562, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@1fc3a85
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
2024-09-25T16:35:51.637+09:00 WARN 34379 --- [MoviePedia] [o-8080-exec-191] .m.m.a.ExceptionHandlerExceptionResolver : Resolved [org.springframework.web.context.request.async.AsyncRequestNotUsableException: ServletOutputStream failed to flush: java.io.IOException: Broken pipe]
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
2024-09-25T16:35:51.638+09:00 WARN 34379 --- [MoviePedia] [o-8080-exec-128] .m.m.a.ExceptionHandlerExceptionResolver : Resolved [org.springframework.web.context.request.async.AsyncRequestNotUsableException: ServletOutputStream failed to flush: java.io.IOException: Broken pipe]
Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=?
.
.
.
2024-09-25T16:35:51.650+09:00 INFO 34379 --- [MoviePedia] [e [_default_]-0] c.s.m.common.cache.CacheEventLogger : Cache event occurred - Key: 2024-09-25T16:35:51.284170, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@6f4c8952
2024-09-25T16:35:51.650+09:00 INFO 34379 --- [MoviePedia] [e [_default_]-0] c.s.m.common.cache.CacheEventLogger : Cache event occurred - Key: 2024-09-25T16:35:50.785935, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@6efe0858
2024-09-25T16:35:51.651+09:00 WARN 34379 --- [MoviePedia] [o-8080-exec-167] .m.m.a.ExceptionHandlerExceptionResolver : Resolved [org.springframework.web.context.request.async.AsyncRequestNotUsableException: ServletOutputStream failed to flush: java.io.IOException: Broken pipe]
2024-09-25T16:35:51.651+09:00 INFO 34379 --- [MoviePedia] [e [_default_]-0] c.s.m.common.cache.CacheEventLogger : Cache event occurred - Key: 2024-09-25T16:35:51.284270, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@26f4a684
로그를 보면 다음과 같은 일이 일어나고 있음을 알 수 있다.
- Cache event occurred - Key: {지정한 캐시 키}, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@1fc3a85
: 캐시가 한번 생성되면 그걸 사용해서 응답을 반환해야 하는데, 계속해서 새로운 캐시를 만들고 있다. Old Value가 null인 것을 보면, 해당 키에 대한 캐시가 처음 생성되었거나, 기존에 캐시된 값이 없는 것으로 보인다. 따라서 만들어진 캐시를 활용하지 못하고 있다. - Hibernate: select distinct m1_0.movie_id,m1_0.description,m1_0.director,g1_0.genre_id,g1_0.genre_name,m1_0.image_url,m1_0.release_date,m1_0.release_state,m1_0.reservation_rate,r1_0.movie_id,r1_0.review_id,r1_0.content,r1_0.member_id,m1_0.title from movie m1_0 left join genre g1_0 on g1_0.genre_id=m1_0.genre_id left join review r1_0 on m1_0.movie_id=r1_0.movie_id Hibernate: select count(m1_0.movie_id) from movie m1_0
더불어 만약 이 쿼리가 캐시된 데이터라면, 동일한 쿼리가 다시 실행되지 않아야 한다. 하지만 여기서는 쿼리가 실행되고 있기 때문에, 캐시가 제대로 활용되지 않은 것이 확실하다. - Hibernate: select m1_0.member_id,m1_0.email,m1_0.nickname,m1_0.password from member m1_0 where m1_0.member_id=? 의 반복
: member 테이블에서 member_id로 회원 정보를 조회하는 SQL 쿼리가 계속 날아간다. 처음에는 loadUserByUsername 때문이라고 생각했지만, 이 메서드는 로그인 시에만 필요하므로 용의선상에서 제외한다. - Resolved [org.springframework.web.context.request.async.AsyncRequestNotUsableException: ServletOutputStream failed to flush: java.io.IOException: Broken pipe]
: 이 오류는 클라이언트가 서버에 연결된 상태에서 갑자기 연결을 끊거나, 서버가 응답을 클라이언트에 전달하기 전에 클라이언트가 응답을 받을 준비가 되지 않은 경우에 발생한다. 서버가 요청을 처리하는 데 시간이 너무 오래 걸려서, 클라이언트가 타임아웃(timeout)된 것으로 보인다. - [MoviePedia] [o-8080-exec-109] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
: 이 경고는 페이징을 사용할 때 firstResult 또는 maxResults가 컬렉션 페치를 사용할 때 제대로 처리되지 않고 메모리에서 처리되었다는 의미이다.
[참고할 사항]
PageRequest.of(page, size)는 내부적으로 setFirstResult()와 setMaxResults()로 변환된다. 각각 OFFSET과 LIMIT 절에 해당한다. Hibernate는 이를 MySQL 쿼리로 변환할 때 SELECT * FROM movie LIMIT 10 OFFSET 0; 과 같은 형식으로 변환한다.
해결1-1 : 캐시키를 바꾸자
@Cacheable(value = "rankings", key = "T(java.time.LocalDateTime).now().toString()")
@Override
public MovieListDto getRanking(int page, int size) {
// 로직...
}
현재의 캐시 키를 보면 요청이 들어오는 시간을 캐시 키로 쓰고 있다. 캐시가 잘 만들어지는지고 TTL이 지나면 사라지는지 시간 단위로 확인하기 위해 설정해 둔 것인데, 이것이 문제의 원인. LocalDateTime.now()는 호출할 때마다 다른 값이 반환되므로, 매 요청마다 캐시 키가 달라지고, 캐시된 데이터를 사용할 수 없다. 따라서 캐시가 적용되지 않고 매번 새로운 키로 데이터가 저장된 것이다.
위처럼 페이징을 해서 보내주는 get요청의 경우, 캐시 키를 page와 size에 기반하여 생성하는 것이 좋다. 이를 통해 동일한 page와 size에 대한 요청은 캐시된 데이터를 사용할 수 있다.
따라서 다음과 같이 캐시키를 변경하였다.
@Cacheable(value = "rankings", key = "#page + '-' + #size")
다시 한번 jmeter를 돌려보자.

이전 성능 결과:
- 117,078개의 요청
- 평균 응답 시간: 676 ms
- 최소 응답 시간: 2 ms, 최대 응답 시간: 4580 ms
- 표준 편차: 312.61 ms
- 초당 처리량: 620.7 requests/sec
- Received: 3464.17 KB/sec, Sent: 81.48 KB/sec
새로운 성능 결과:
- 1,179,486개의 요청 (약 10배 증가)
- 평균 응답 시간: 139 ms (약 5배 감소)
- 최소 응답 시간: 0 ms, 최대 응답 시간: 4580 ms (최대 응답 시간은 동일)
- 표준 편차: 206.85 ms (이전보다 낮아짐, 응답 시간 변동성이 줄어듦)
- 초당 처리량: 523.8 requests/sec (약간 감소)
- Received: 2929.22 KB/sec, Sent: 69.03 KB/sec (수신 및 송신 데이터도 약간 감소)
평균 응답 시간이 676ms에서 139ms로 약 5배 줄어들고, 처리하는 요청의 수가 10만에서 100만으로 약 10배 증가하였다. 무엇보다 에러량이 0.43%에서 0.04%로 줄어들었다. 하지만 최대 응답 시간은 동일하며, 여전히 에러가 존재하는 상태이다.
해결1-2: 쿼리 수정하기
@Cacheable(value = "rankings", key = "#page + '-' + #size")
@Override
public MovieListDto getRanking(int page, int size) {
Pageable pageable = PageRequest.of(page, size);
Page<Movie> moviePage = movieRepository.findAllWithReviewsAndGenre(pageable);
List<MovieDto> movieDtoList = moviePage.stream()
.map(movie -> {
List<ReviewList> reviewList = movie.getReviews().stream()
.map(review -> ReviewList.builder()
.content(review.getContent())
.nickname(review.getMember().getNickname())
.build())
.collect(Collectors.toList());
return MovieDto.fromEntity(movie, reviewList);
})
.collect(Collectors.toList());
return new MovieListDto(movieDtoList, (int) moviePage.getTotalElements());
}
@Query(value = "SELECT DISTINCT m FROM Movie m LEFT JOIN FETCH m.genre LEFT JOIN FETCH m.reviews",
countQuery = "SELECT COUNT(m) FROM Movie m")
Page<Movie> findAllWithReviewsAndGenre(Pageable pageable);
각각 서비스, 레포지토리의 코드다.
아무런 문제도 없다고 생각했는데… 코드를 자세히 읽어보니, 멤버를 조회하는 반복적인 쿼리의 이유를 찾을 수 있었다.
작성한 jpql 쿼리에서 member 테이블을 fetch join 하지 않아서, review.getMember()를 할 때마다 멤버를 찾는 쿼리가 날아갔던 것. 즉 N+1문제가 일어나고 있었다.
따라서 쿼리를 아래와 같이 수정하였다. 추가된 부분은 m.reviews r LEFT JOIN FETCH r.member
@Query(value = "SELECT DISTINCT m FROM Movie m LEFT JOIN FETCH m.genre LEFT JOIN FETCH m.reviews r LEFT JOIN FETCH r.member",
countQuery = "SELECT COUNT(m) FROM Movie m")
Page<Movie> findAllWithReviewsAndGenre(Pageable pageable);
다시 Jmeter로 향한다.

이전 성능 결과:
- 1,179,486개의 요청
- 평균 응답 시간: 139 ms
- 최대 응답 시간: 4580 ms
- 표준 편차: 206.85 ms
- 초당 처리량: 523.8 requests/sec
- Received: 2929.22 KB/sec, Sent: 69.03 KB/sec
- 요청당 평균 데이터 크기: 5726.5 bytes
새로운 성능 결과:
- 1,076,090개의 요청
- 평균 응답 시간: 78 ms (약 44% 감소)
- 최대 응답 시간: 486 ms (약 90% 감소. 일부 요청에서 매우 긴 지연 시간이 있었던 문제가 해결됨.)
- 표준 편차: 32.05 ms (약 85%감소. 응답 시간의 일관성 대폭 개선)
- 초당 처리량: 5375.7 requests/sec (약 10배 증가. 서버의 처리 성능 대폭 향상)
- Received: 30,068.94 KB/sec, Sent: 708.71 KB/sec (네트워크 입출력 성능 대폭 향상)
- 요청당 평균 데이터 크기: 5727.7 bytes (거의 동일)
이제 더 이상 에러가 터지지 않는다! 139ms에서 78ms로 평균 응답 시간이 약 반으로 줄어들었다. 더 이상 멤버를 찾는 쿼리도 날아가지 않았다.
2024-09-25T23:17:36.790+09:00 WARN 40108 --- [MoviePedia] [nio-8080-exec-1] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
Hibernate: select distinct m1_0.movie_id,m1_0.description,m1_0.director,g1_0.genre_id,g1_0.genre_name,m1_0.image_url,m1_0.release_date,m1_0.release_state,m1_0.reservation_rate,r1_0.movie_id,r1_0.review_id,r1_0.content,r1_0.member_id,m2_0.member_id,m2_0.email,m2_0.nickname,m2_0.password,m1_0.title from movie m1_0 left join genre g1_0 on g1_0.genre_id=m1_0.genre_id left join review r1_0 on m1_0.movie_id=r1_0.movie_id left join member m2_0 on m2_0.member_id=r1_0.member_id
Hibernate: select count(m1_0.movie_id) from movie m1_0
2024-09-25T23:17:36.990+09:00 INFO 40108 --- [MoviePedia] [e [_default_]-0] c.s.m.common.cache.CacheEventLogger : Cache event occurred - Key: 0-10, Old Value: null, New Value: com.supershy.moviepedia.movie.dto.MovieListDto@2a086c36
문제 2: firstResult/maxResults specified with collection fetch; applying in memory
쿼리 결과를 전부 메모리에 적재한 뒤, Pagination 작업을 진행하기 때문에 위험하다는 로그가 남아 있다. 로직에 따르면 이미 Pagination된 결과를 들고올 것인데, 왜 이런 경고가 발생하는 것인지 의문이 든다.
Hibernate:
select distinct
m1_0.movie_id,
m1_0.description,
m1_0.director,
g1_0.genre_id,
g1_0.genre_name,
m1_0.image_url,
m1_0.release_date,
m1_0.release_state,
m1_0.reservation_rate,
r1_0.movie_id,
r1_0.review_id,
r1_0.content,
r1_0.member_id,
m2_0.member_id,
m2_0.email,
m2_0.nickname,
m2_0.password,
m1_0.title
from movie m1_0
left join genre g1_0 on g1_0.genre_id=m1_0.genre_id
left join review r1_0 on m1_0.movie_id=r1_0.movie_id
left join member m2_0 on m2_0.member_id=r1_0.member_id
날아가는 쿼리를 살펴보자, 이상하게도 페이징에 필요한 limit 절이 보이지 않는다!!!
테스트용 코드를 만들어서 비교해보자.
@Override
public List<MovieDto> test() {
Pageable pageable = PageRequest.of(0, 10);
Page<Movie> moviePage = movieRepository.findAll(pageable);
List<MovieDto> movieList = new ArrayList<>();
for(Movie movie : moviePage) {
movieList.add(new MovieDto(movie));
}
return movieList;
}
아무런 join fetch 없이 pagination을 요구하는 코드다. 쿼리는 아래처럼 limit과 함께 날아간다.
select
m1_0.movie_id,
m1_0.description,
m1_0.director,
m1_0.genre_id,
m1_0.image_url,
m1_0.release_date,
m1_0.release_state,
m1_0.reservation_rate,
m1_0.title
from movie m1_0
limit ?,?
왜 이럴까?
Hibernate User Guide 17.8.4. join fetch for association fetching 섹션에서는 fetch join과 pagination을 함께 사용하지 않기를 권고한다.

17.13.1 limits and offsets 섹션에서 이와 관련된 이야기(+정확히 내가 마주한 상황에 대한 이야기)를 좀 더 찾아볼 수 있다.


페이징과 페치 조인을 함께 사용할 경우, Hibernate는 데이터베이스에서 조건에 맞는 모든 결과를 가져온 다음 메모리에서 직접 limit을 적용한다. 즉, 데이터베이스에서 제한된 결과만 가져오는 것이 아니라, 모든 데이터를 불러온 후 메모리에서 잘라내는 방식으로 동작한다.
DB에서 10개만 들고오는 게 아니라, 테이블을 통째로 들고와 메모리에 올린 후 10개를 잘라내는 식으로 동작하기 때문에 성능 측면에서 매우 좋지 않다는 뜻이다.
이에 대한 대안으로, hibernate는 다음 섹션에서 CTE(Common Table Expression)를 소개한다. (이 방법은 사용하지 않기로 결정했는데, 이유는 아래에 서술한다.)
CTE는 한 번 계산한 결과를 쿼리 내에서 재사용할 수 있게 해준다. 쿼리가 실행될 때만 잠깐 존재하고, 쿼리가 끝나면 사라지는데, 복잡한 계산을 미리 한 다음 그걸 다른 쿼리에서 여기저기 쓸 수 있게 한다. 쉽게 말하면… 뷰다.
WITH MyCTE AS (
SELECT name FROM students WHERE grade = 'A'
)
SELECT * FROM MyCTE;
이렇게 하면 성적이 A인 학생들만 찾아서 MyCTE에 넣어 두고 다른 쿼리에서 사용이 가능하다.
이를 해당 메서드에 적용해보면 다음과 같은 쿼리가 나온다. 네이티브 쿼리를 쓰기 때문에 코드가 매우 복잡하다.
@Cacheable(value = "rankings", key = "#page + '-' + #size")
@Override
public MovieListDto getRanking(int page, int size) {
int startRow = page * size + 1;
int endRow = (page + 1) * size;
List<Object[]> results = movieRepository.findAllWithReviewsAndGenreNative(startRow, endRow);
long totalElements = movieRepository.countMovies();
Map<Long, MovieDto> movieDtoMap = new LinkedHashMap<>();
for (Object[] result : results) {
Long movieId = ((Number) result[0]).longValue();
Timestamp timestamp = (Timestamp) result[6];
LocalDateTime releaseDate = (timestamp != null) ? timestamp.toLocalDateTime() : null;
MovieDto movieDto = movieDtoMap.computeIfAbsent(movieId, k -> MovieDto.builder()
.movieId(movieId)
.title((String) result[1])
.description((String) result[2])
.director((String) result[3])
.reservationRate((Double) result[4])
.imageUrl((String) result[5])
.releaseDate(releaseDate)
.genre((String) result[7])
.reviewList(new ArrayList<>())
.build());
if (result[8] != null) {
movieDto.getReviewList().add(ReviewList.builder()
.content((String) result[8])
.nickname((String) result[9])
.build());
}
}
List<MovieDto> movieDtoList = new ArrayList<>(movieDtoMap.values());
return new MovieListDto(movieDtoList, (int) totalElements);
}
@Query(nativeQuery = true, value =
"WITH movie_cte AS ( " +
" SELECT m.movie_id, m.title, m.description, m.director, m.reservation_rate, m.image_url, m.release_date, " +
" g.genre_name, " +
" ROW_NUMBER() OVER (ORDER BY m.movie_id) AS row_num " +
" FROM movie m " +
" LEFT JOIN genre g ON m.genre_id = g.genre_id " +
"), " +
"ranked_movies AS ( " +
" SELECT * " +
" FROM movie_cte " +
" WHERE row_num BETWEEN :startRow AND :endRow " +
"), " +
"movie_reviews AS ( " +
" SELECT r.movie_id, r.content AS review_content, mb.nickname AS reviewer_nickname " +
" FROM review r " +
" JOIN member mb ON r.member_id = mb.member_id " +
" WHERE r.movie_id IN (SELECT movie_id FROM ranked_movies) " +
") " +
"SELECT rm.movie_id, rm.title, rm.description, rm.director, rm.reservation_rate, rm.image_url, rm.release_date,\n" +
" rm.genre_name, mr.review_content, mr.reviewer_nickname " +
"FROM ranked_movies rm " +
"LEFT JOIN movie_reviews mr ON rm.movie_id = mr.movie_id " +
"ORDER BY rm.movie_id, mr.review_content")
List<Object[]> findAllWithReviewsAndGenreNative(@Param("startRow") int startRow, @Param("endRow") int endRow);
@Query(nativeQuery = true, value = "SELECT COUNT(DISTINCT m.movie_id) FROM movie m")
long countMovies();
hibernate memory 관련 워닝은 더이상 뜨지 않았지만, execution plan을 살펴 보았을 때 full scan이 3번이나 들어가 비효율적이며, 가독성 측면에서도 이렇게 코드를 작성하는 건 좋지 않다고 결론내렸다. (쿼리를 제대로 작성한 건지도 의문이었다…. 결과가 나오긴 하지만…)
해결2: join fetch와 pagination을 사용할 때 제대로 pagination이 되지 않는 문제를 해결하는 세 가지 방법
구글링 결과, 다음의 방법들을 찾을 수 있었다.
- EntityGraph 사용하기
- @BatchSize + 쿼리 분리하기
- 쿼리 분리 및 쿼리 단계에서 DTO로 바로 매핑하기
각각의 코드를 작성하고 성능 비교를 위해 캐시를 제거하였다.
총 영화는 1114개, 멤버는 114개, 리뷰는 1100개의 데이터로 진행하였다.
| 처리한 요청의 수 | 평균 응답 시간 | 초당 처리량 | |
| join fetch + pagination | 15140 | 5749ms | 72.8/sec |
| Entity Graph 사용 | 12926 | 6749ms | 61.9/sec |
| @BatchSize + 쿼리 분리 | 147888 | 576ms | 736.0/sec |
| 쿼리 단계에서 DTO 매핑 + 쿼리 분리 + @BatchSize | 198345 | 429ms | 987.2/sec |
1) EntityGraph 사용
@NamedEntityGraph(name = "Movie.withReviewsAndGenre",
attributeNodes = {
@NamedAttributeNode("genre"),
@NamedAttributeNode(value = "reviews", subgraph = "reviewsWithMember")
},
subgraphs = {
@NamedSubgraph(name = "reviewsWithMember", attributeNodes = @NamedAttributeNode("member"))
}
)
public class Movie {
// 생략
}public MovieListDto getRanking(int page, int size) {
Pageable pageable = PageRequest.of(page, size);
// 1. 영화 리뷰 장르 멤버를 한번에 가져오기
Page<Movie> moviePage = movieRepository.findAllWithEntityGraph(pageable);
List<Movie> movies = moviePage.getContent();
List<MovieDto> movieDtoList = movies.stream()
.map(movie -> {
List<ReviewList> reviewList = movie.getReviews().stream()
.map(review -> ReviewList.builder()
.content(review.getContent())
.nickname(review.getMember().getNickname())
.build())
.collect(Collectors.toList());
return MovieDto.fromEntity(movie, reviewList);
})
.collect(Collectors.toList());
return new MovieListDto(movieDtoList, (int) moviePage.getTotalElements());
}@EntityGraph(attributePaths = {"genre", "reviews.member"})
@Query("SELECT m FROM Movie m")
Page<Movie> findAllWithEntityGraph(Pageable pageable);// 무턱대고 다 가져오는 모습
select
m1_0.movie_id,
m1_0.description,
m1_0.director,
g1_0.genre_id,
g1_0.genre_name,
m1_0.image_url,
m1_0.release_date,
m1_0.release_state,
m1_0.reservation_rate,
r1_0.movie_id,
r1_0.review_id,
r1_0.content,
r1_0.member_id,
m2_0.member_id,
m2_0.email,
m2_0.nickname,
m2_0.password,
m1_0.title
from movie m1_0
left join genre g1_0 on g1_0.genre_id=m1_0.genre_id
left join review r1_0 on m1_0.movie_id=r1_0.movie_id
left join member m2_0 on m2_0.member_id=r1_0.member_id
EntityGraph는 설정된 연관 엔티티를 모두 left join으로 로드하여 가져오는데, 이때도 보면 limit가 적용되지 않은 걸 볼 수 있다. 또한 로그에서도 이전과 같은 에러가 뜬다.
2024-09-27T20:52:50.148+09:00 WARN 14497 --- [MoviePedia] [nio-8080-exec-7] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
Hibernate: select m1_0.movie_id,m1_0.description,m1_0.director,g1_0.genre_id,g1_0.genre_name,m1_0.image_url,m1_0.release_date,m1_0.release_state,m1_0.reservation_rate,r1_0.movie_id,r1_0.review_id,r1_0.content,r1_0.member_id,m2_0.member_id,m2_0.email,m2_0.nickname,m2_0.password,m1_0.title from movie m1_0 left join genre g1_0 on g1_0.genre_id=m1_0.genre_id left join review r1_0 on m1_0.movie_id=r1_0.movie_id left join member m2_0 on m2_0.member_id=r1_0.member_id
Hibernate: select count(m1_0.movie_id) from movie m1_0
2) @BatchSize + 쿼리 분리
BatchSize 어노테이션은 클래식한 N+1 문제 해결법 중에 하나로 많이 거론된다. join fetch를 사용하지 않도록 도와주는 친구다.
public class Movie {
// 나머지 필드들...
@BatchSize(size = 10)
@OneToMany(mappedBy = "movie", fetch = FetchType.LAZY)
private List<Review> reviews;
}
@Service
public class MovieServiceImpl implements MovieService {
private final MovieRepository movieRepository;
@Override
public MovieListDto getRanking(int page, int size) {
Pageable pageable = PageRequest.of(page, size);
// 1. 영화만 페이징하여 가져오기
Page<Movie> moviePage = movieRepository.findPagedMovies(pageable);
List<Movie> movies = moviePage.getContent();
// 2. 해당 영화의 리뷰(batch size 10)와 장르를 로드하기
movieRepository.findMoviesWithReviewsAndGenreInBatch(movies);
List<MovieDto> movieDtoList = movies.stream()
.map(movie -> {
List<ReviewList> reviewList = movie.getReviews().stream()
.map(review -> ReviewList.builder()
.content(review.getContent())
.nickname(review.getMember().getNickname())
.build())
.collect(Collectors.toList());
return MovieDto.fromEntity(movie, reviewList);
})
.collect(Collectors.toList());
// 결과 반환
return new MovieListDto(movieDtoList, (int) moviePage.getTotalElements());
}
}@Query("SELECT m FROM Movie m")
Page<Movie> findPagedMovies(Pageable pageable);
@Query("SELECT m FROM Movie m " +
"LEFT JOIN FETCH m.genre " +
"LEFT JOIN FETCH m.reviews r " +
"LEFT JOIN FETCH r.member " +
"WHERE m IN :movies")
List<Movie> findMoviesWithReviewsAndGenreInBatch(@Param("movies") List<Movie> movies);
// 1. limit 절을 사용해 먼저 10개의 영화만 로드한 후
select
m1_0.movie_id,
m1_0.description,
m1_0.director,
m1_0.genre_id,
m1_0.image_url,
m1_0.release_date,
m1_0.release_state,
m1_0.reservation_rate,
m1_0.title
from movie m1_0
limit ?
// 2. 총 개수를 세는 count query를 날린다.
select count(m1_0.movie_id) from movie m1_0
// 3. 이후 영화, 장르, 리뷰, 멤버 엔티티를 로드하는데, 10개의 영화에 대해서만 로드!
select m1_0.movie_id,m1_0.description,m1_0.director,g1_0.genre_id,g1_0.genre_name,m1_0.image_url,m1_0.release_date,m1_0.release_state,m1_0.reservation_rate,r1_0.movie_id,r1_0.review_id,r1_0.content,r1_0.member_id,m2_0.member_id,m2_0.email,m2_0.nickname,m2_0.password,m1_0.title from movie m1_0 left join genre g1_0 on g1_0.genre_id=m1_0.genre_id left join review r1_0 on m1_0.movie_id=r1_0.movie_id left join member m2_0 on m2_0.member_id=r1_0.member_id where m1_0.movie_id in (?,?,?,?,?,?,?,?,?,?
3) @BatchSize + 쿼리 분리 및 쿼리 단계에서 DTO에 바로 매핑
BatchSize 10은 그대로 적용하고 서비스와 레포지토리 코드를 바꾼다.
@Override
public MovieListDto getRanking(int page, int size) {
Pageable pageable = PageRequest.of(page, size);
// 1. 영화 목록을 DTO로 가져오기 (딱 10개만 먼저 들고온다)
Page<MovieDto> movieDtos = movieRepository.findMovies(pageable);
// 2. 영화id 리스트를 가지고 영화 리뷰들을 로드하기
List<Long> movieIds = movieDtos.stream()
.map(MovieDto::getMovieId)
.collect(Collectors.toList());
List<ReviewList> reviews = reviewRepository.findReviewsByMovieIds(movieIds);
movieDtos.forEach(movieDto -> {
List<ReviewList> movieReviews = reviews.stream()
.filter(review -> review.getMovieId().equals(movieDto.getMovieId()))
.collect(Collectors.toList());
movieDto.setReviewList(movieReviews);
});
return new MovieListDto(movieDtos.getContent(), (int) movieDtos.getTotalElements());
}@Query("SELECT new com.supershy.moviepedia.movie.dto.MovieDto(m.movieId, m.title, m.genre.genreName, m.description, m.director, m.reservationRate, m.imageUrl, m.releaseDate) " +
"FROM Movie m")
Page<MovieDto> findMovies(Pageable pageable);
@Query("SELECT new com.supershy.moviepedia.movie.dto.ReviewList(r.movie.movieId, r.content, r.member.nickname) " +
"FROM Review r WHERE r.movie.movieId IN :movieIds")
List<ReviewList> findReviewsByMovieIds(List<Long> movieIds);
// 1. 영화와 장르만 조인해서 10개의 영화를 가져온다
select
m1_0.movie_id,
m1_0.title,
g1_0.genre_name,
m1_0.description,
m1_0.director,
m1_0.reservation_rate,
m1_0.image_url,
m1_0.release_date
from movie m1_0
join genre g1_0 on g1_0.genre_id=m1_0.genre_id
limit ?
// 2. count query
select count(m1_0.movie_id) from movie m1_0
// 3. 이후 리뷰의 멤버만 조인해서 필요한 자료들을 들고온다
select r1_0.movie_id,r1_0.content,m2_0.nickname from review r1_0 join member m2_0 on m2_0.member_id=r1_0.member_id where r1_0.movie_id in (?,?,?,?,?,?,?,?,?,?)
이중 쿼리 단계에서 DTO 매핑 + 쿼리 분리 + @BatchSize 가 가장 성능이 좋은 것을 확인할 수 있다!
결론: 그래서 캐시는 성능에 얼마나 영향을 줄까?
DTO 매핑 + 쿼리 분리 + @BatchSize를 모두 적용한 상태에서 캐시를 추가하고 성능을 비교해본다.
| 처리한 요청의 수 | 평균 응답 시간 | 초당 처리량 | |
| 캐시 전 | 198345 | 429ms | 987.2/sec |
| 캐시 후 | 1325583 | 64ms | 6622.9/sec |

- 처리한 요청의 수:
- 569.1% 증가: 캐시 적용 후 서버가 6배 이상의 요청을 처리하였다.
- 평균 응답 시간:
- 85.1% 감소: 캐시로 인해 응답 시간이 크게 줄어들었다.
- 초당 처리량:
- 570.7% 증가: 초당 처리할 수 있는 요청이 약 6.7배 증가하였다.
캐시로 성능이 크게 향상된 것을 확인할 수 있었다!
'스프링' 카테고리의 다른 글
| [아이북조아] 최종 발표 자료 및 아이북조아를 마치며 (5) | 2025.01.05 |
|---|---|
| 좋아요 테이블, 어떻게 구성하면 좋을까? PK 2개 vs. PK 1개(feat.FK 2개) (4) | 2024.11.13 |
| AOP & 캐시 적용하기 (0) | 2024.09.30 |
| 테스트 코드 8 - 토스 결제 API 테스트 코드 작성하기 (0) | 2024.09.16 |
| [유레카] 떠오르는대로(!) 정리하는 유레카 수업 2 : MyBatis 사용하기 (0) | 2024.09.10 |


